2020. 5. 11. 22:38ㆍJava
객체와 개체
일반적으로 JAVA를 사용하여 코딩을 한다고 하면 객체지향을 활용하게 된다. 이때 객체(Object)는 다른 객체들과 관계를 맺게 된다. 하지만 DB에 저장되는 것은 개체(Entity)이기 때문에 이를 대응시켜주는 기술이 필요하다. Spring Data JDBC는 이러한 방법을 제공한다(링크). 그런데 공식문서의 예시는 너무 빈약하다. 그래서 혼자 이것저것 공부하면서 알아낸 내용들을 풀어보려고 한다. 사용한 버전은 2.0.1RELEASE 버전이다.
기본적인 사용법
// Person.java
public class Person {
@Id
private Long personId;
private final String personName;
private int age;
Person(Long personId, String personName, int age) {
this.personId = personId;
this.personName = personName;
this.age = age;
}
public static Person from(String name, int age) {
return new Person(null, name, age);
}
...
}
// PersonRepository.java
public interface PersonRepository extends CrudRepository<Person, Long> {
}// schema.sql
create table if not exists person
(
person_id bigint primary key auto_increment not null,
person_name varchar(20),
age int
);- 객체에서 Id가 되는 필드에는
@Id어노테이션을 붙여준다(우선, DB에서 id 필드를 auto_increment로 처리한 경우만 살펴본다). - 객체의 필드에
final키워드가 사용 가능하다. - 생성자 전략에는 여러 가지가 있지만 여기서는 가장 권장되는 방법(링크)만을 얘기하겠다.
모든 필드를 갖는 하나의 생성자(all-args one constructor)만 존재하는 방식이다. 생성자는 반드시 하나만 존재해야한다. - JPA와는 다르게 DDL 기능이 없으므로 직접
schema.sql을 작성해줘야한다. - 객체의 클래스명과 필드명은 camelCase로, 스키마의 테이블명과 컬럼명은 snake_case로 작성해야한다.
- CrudRepository의 제네릭은
<EntityClass, Id type>이다. 여기서는 id가Long이므로<Person, Long>이 된다.
테스트 코드는 다음과 같이 작성할 수 있다.
Person person = Person.from("효혁", 26);
personRepository.save(person);
assertThat(person.getPersonId()).isNotNull();
Person persistPerson = personRepository.findById(1L).get();
assertThat(persistPerson).isEqualTo(person);
person.setAge(27);
personRepository.save(person);
Person persistPersonOlder = personRepository.findById(1L).get();
assertThat(persistPersonOlder.getAge()).isEqualTo(27);
personRepository.delete(person);
assertThat(personRepository.findAll()).hasSize(0);save메서드는INSERT또는UPDATE를 실행한다.@Id필드가null이라면INSERT를 실행한다.@Id필드가null이 아니라면UPDATE를 실행한다.
save메서드는 파라미터로 받은 객체를 변경시킨다. 세번째 줄에서person의personId가null이 아님을 확인할 수 있다.CrudRepository는save,findById,findAll,findAllById,delete,deleteById등의 기본적인 메서드를 제공한다.
One-To-Many (Cascade)
하나의 글(Article)이 여러 개의 댓글(Comment)를 갖는 경우를 생각해보자.
// Article.java
public class Article {
@Id
private Long id;
private String author;
private Set<Comment> comments;
public static Article of(String author) {
return new Article(null, author, new HashSet<>());
}
...
}
// Comment.java
public class Comment {
private String content;
...
}// schema.sql
create table if not exists article
(
id bigint primary key auto_increment,
author varchar(50)
);
create table if not exists comment
(
content varchar(255),
article bigint
);Spring Data JDBC는 One-To-Many 관계를 Set을 사용하여 나타낸다.
객체에서는 One에 해당하는 Article이 Many에 해당하는 Comment들을 Set으로 갖고 있다. 이와 반대로, DDL에서 Many에 해당하는 comment 테이블이 article이라는 필드로 연관관계를 맺고 있다.
따라서, Many에 해당하는 테이블(comment)에 One에 해당하는 클래스의 이름(Article)을 snake_case로 갖는 컬럼(article)을 추가해주기만 하면 된다.

테스트 코드는 다음과 같다.
Article article = Article.of("효혁");
article.addComment(new Comment("글 잘봤어요!"));
article.addComment(new Comment("좋은 글이네요:)"));
articleRepository.save(article);
Article persistArticle = articleRepository.findById(1L).get();
assertThat(persistArticle.getComments()).hasSize(2);findById 메서드로 검색할 때, 따로 필드에 해당하는 Set<Comment> comments 를 조회하는 쿼리가 존재하지 않는다. 하지만 comments의 크기가 2인 것으로 보아 comments들도 같이 조회된 것으로 짐작할 수 있다.
Map
Map 역시 one-to-many 관계를 표현한다.
체스 판 위에 놓여 있는 말들을 다음과 같이 Map으로 나타낼 수 있다. 이 때, key는 말의 위치가 되고, value는 말이 될 것이다.
예를 들어, "e7" 위치에 있는 Queen은 boards.put("e7", new Piece("Queen"))과 같이 나타낼 수 있다.
public class Chess {
@Id
private Long id;
private Map<String, Piece> boards;
...
}
public class Piece {
private String name;
...
}create table if not exists chess
(
id bigint primary key auto_increment
);
create table if not exists piece
(
name varchar(30),
chess bigint,
chess_key varchar(20)
);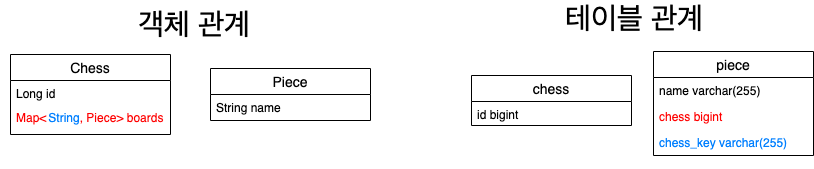
Map의 key는 simple type 이다. 여기서 simple type이란 원시 자료형의 Wrapper 객체들, String, Enum을 의미한다.
Map의 value는 다른 개체(Entity)가 올 수 있다.
Map의 value에 해당하는 개체의 DDL에는 Set과 마찬가지로 종속되는 테이블의 id가 클래스 이름의 snake_case 형태의 컬럼으로 존재한다.
또, Map의 key에 해당하는 '클래스명_key' 이름의 컬럼 역시 필요하다.여기서 piece 테이블은 종속되는 테이블의 이름(chess)과 key에 해당하는 위치 정보(chess_key)를 갖는다.
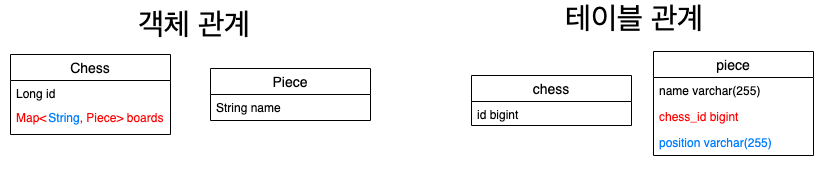
컬럼명에 조금더 의미를 부여하고 싶다면 다음과 같이@MappedCollection을 사용하면 된다.
public class Chess {
@Id
private Long id;
@MappedCollection(idColumn = "CHESS_ID", keyColumn = "POSITION")
private Map<String, Piece> boards;
...
}create table if not exists piece
(
name varchar(30),
chess_id bigint,
position varchar(20)
);
테스트 코드는 다음과 같다.
Map<String, Piece> boards = new HashMap<>();
boards.put("a1", new Piece("Rook"));
boards.put("a2", new Piece("Pawn"));
boards.put("b1", new Piece("Knight"));
boards.put("c1", new Piece("Bishop"));
Chess chess = new Chess(boards);
chessRepository.save(chess);
Chess persistChess = chessRepository.findById(1L).get()
assertThat(persistChess.getBoards()).isEqualTo(boards);역시 boards를 따로 저장하지 않고 Chess만 저장했지만, Chess만 불러와도 boards도 같이 조회되는 것을 확인할 수 있다.
List
List를 다르게 표현하면 순서가 있는 Set이라고 할 수 있다. 즉, Map<Integer(순서), Entity>처럼 표현되기 때문에 실제 개체에서 표현 방식은 Map과 동일하다.
앞서 Article과 Comment의 관계를 List로 바꿔보자.
// Article.java
public class Article {
@Id
private Long id;
private String author;
private List<Comment> comments;
public static Article of(String author) {
return new Article(null, author, new ArrayList<>());
}
...
}
// Comment.java
public class Comment {
private String content;
...
}// schema.sql
create table if not exists article
(
id bigint primary key auto_increment,
author varchar(50)
);
create table if not exists comment
(
content varchar(255),
article bigint,
article_key bigint
);Map과 DDL 작성법이 완전 동일하다. 앞서 작성한 테스트를 실행하면 통과하는 것을 확인할 수 있다.
Embedded
객체 안의 List, Set 등은 일급 컬렉션으로 포장하는 것이 좋다. 그럴 경우, 새로 테이블을 만들 필요 없이 @Embedded를 활용하면 기존 테이블과 컬럼을 유지한 채 작업이 가능하다. 아래 수정된 코드를 보자.
// Article.java
public class Article {
@Id
private Long id;
private String author;
@Embedded.Nullable
private Comments comments;
public static Article of(String author) {
return new Article(null, author, Comments.empty());
}
...
}
// Comments.java
public class Comments {
@MappedCollection(keyColumn = "ARTICLE_KEY")
private List<Comment> comments;
public static Comments empty() {
return new Comments(new ArrayList<>());
}
...
}Comments라는 일급 컬렉션을 만들었다. 이 때, 한 가지 유의해야할 점은 Comments의 필드가 List이기 때문에 리스트의 순서를 나타내는 keyColumn의 이름을 수정해줘야된다는 점이다. 따라서 @MappedCollection으로 알맞게 이름을 수정해준다. 또 Article 클래스의 일급 컬렉션 위에 @Embedded.Nullable 어노테이션을 붙이면 작업이 끝난다. DDL을 수정할 필요없이 일급 컬렉션 구현이 가능함을 알 수 있다.
'Java' 카테고리의 다른 글
| [WebClient] @RestClientTest를 WebFlux에서 사용하기 (0) | 2020.07.11 |
|---|---|
| [Spring Data JDBC] Id 삽입 전략 (0) | 2020.07.03 |
| JPA vs JDBC, JPA vs Mybatis, JPA vs Spring Data JPA의 차이점과 Hibernate (0) | 2020.04.25 |
| 자바의 생성자와 정적 팩토리 메서드 (0) | 2020.04.20 |
| Intelij 단축키 - 알아두면 생산성이 올라가는 단축키 모음 (0) | 2020.04.20 |